Background
The objective of this exercise was to create an estimate of the cost each county in Wisconsin has to pay in order to transport frac sand from the mine to the nearest railroad terminal. Network analysis helped in determining which rail terminals were closest to each mine. This is one of the many practical ways network analysis can be utilized.
Specifically, network analysis was run on the mines that were active, did not have loading stations on site, and that were at least 1.5 kilometers away from a rail station because then it was assumed the mine would directly load the sand onto the rails for transport. A python script was created to query the mines to produce a final feature class with all of the qualifying mines.
Methods
Python
The following python script shows the process of selecting mines based on certain criteria:
- The mine must be active
- The mine cannot have its own loading station
- The mine has to be at least 1.5 kilometers away from a railroad terminal
Starting the script it was necessary to define the variables for the feature classes. For example, the variable set for the active_mines feature class was "act". Setting the variables ahead of time organizes the inputs and outputs while simplifying the script.
The next step in python was to add field delimiters which provide the correct field information when creating an SQL statement. Field delimiters tell the program what field to search in. In this case "field1" dictated that when "field1" is coded in the script the field "SITE_STATU" in the attribute table is where the information will be found.
Then, SQL statements were built to select active mines and only mines that did not have on-site loading stations.
The SelectLayerByLocation tool was used to query out the mines that were within a distance of 1.5 kilometers of a rail station.
Finally, the CopyFeatures tool was scripted to make a feature class for the mines that met all the criteria above.
 |
| Figure 1. Python script used to select mines for network analysis. |
After the python script was successfully completed network analysis could be performed to find the quickest routes from the mines to the rail terminals.
The network analyst toolbar was added to ArcMap. A streets network was added to the map along with the mines feature class (created from the python script) and the selected Wisconsin rail terminals feature class. In the network analyst toolbar, "New Closest Facility" was chosen to create the trucking routes. The mines were loaded into the analyst as incidents while the rail terminals were loaded as facilities.
Solving the network produced overlapping routes, which is what is desired, compared to all of the routes combining when they reach a common point. This ensures that each route will have its own attributes and have a unique distance for each mine to the terminal.
Model Builder
Model builder was used to find the distances (in miles) of each route and also to find the estimated cost each county to transport the frac sand.
In model builder first the "Make Closest Facility Layer" tool was added with input of the streets feature class. The "Add Locations" tool was selected twice to make the mines the incidents layer and the rail terminals as the facilities. Then, the "Solve" tool ran to create the routes. Reference FIGURE to review the process. This produced the same result as above when the routes were solved for from the network analyst toolbar.
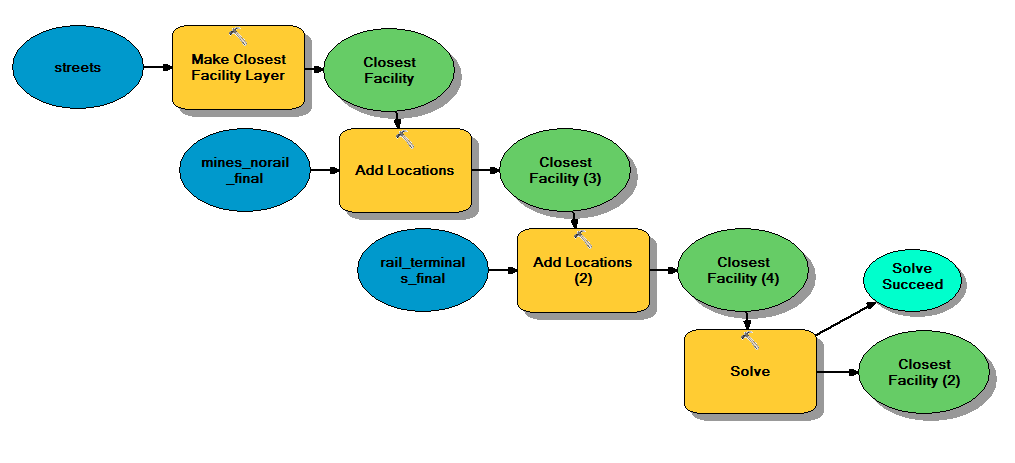 |
| Figure 2. Model builder displaying the creation of routes from the mines to the closest rail terminal. |
With the routes created it was necessary to add the routes to the database using the "Select Data" and "Copy Features" tools to produce a routes feature class. In order to determine the distance traveled and cost for each county, the "Intersect" tool was used to combine these features, however, first the routes and counties feature class were projected with UTM Zone 15N.
 |
| Figure 3. Model builder showing the projection and the intersection of the routes and counties feature classes. |
Since the counties and routes were intersected it was possible to predict the distance traveled in each county and also the estimated cost to transport the sand. The "Summary Statistics", "Add Field", and Calculate Field" tools were used to create a table that included the distance traveled in miles and the cost for each county (Figure 4). The distance traveled for each county was estimated with the "Calculate Field" tool and assigning the following equation [Shape_Length] * 100 (50 truck loads/year * 2 to account for the round trip) * 0.000621371 (miles in a meter). To estimate the costs for each county the equation was multiplied by 0.022, assuming it is roughly 2.2 cents for each truck per mile to transport the sand.
 |
| Figure 4. Model builder displaying the use of various tools to create a table showing the cost and distance of the sand in each county. |
Figure 5 shows the final data flow model used from solving the network analysis to estimating the distance and cost of transporting sand for each county.
 |
| Figure 5. Final data flow model. |
Results
 |
| Figure 6. Map displaying the routes from the mines to the rail terminals in Wisconsin. |
 |
| Table 1. Results from the data flow model in adding fields to determine the total distance travel in miles and the cost estimate per county in dollars. |
It is evident in Figure 7 that Chippewa, Eau Claire, and Barron counties have the highest estimate cost for transporting the sand. This could be attributed to the fact that in these counties the routes extend throughout most of the county. With more distance to be traveled in these counties the higher the cost would be to transport the material. Also, in Chippewa County and Eau Claire County multiple mine connect to a central rail terminal within the county (Figure 6), so there would be a lot of traffic associated to these routes as well. In the counties that experience little cost could be due to the fact that a mine or rail terminal lies right inside the county border, so the distance would be minimal for that county, as the case for Douglas County for example.
 |
| Figure 7. Graph representing the estimated cost associated in each county for the transport of frac sand. |
Conclusion
To conclude using network analysis is a very powerful tool in answering many applied questions such as estimating the cost per county to transport a material. The ability to understand and successfully manage the data in network analysis and the data flow model to create the final output is crucial in determining accurate conclusions. This exercise challenged way the small details would affect the whole project, but helped me realize the applications network analysis can have.
To conclude using network analysis is a very powerful tool in answering many applied questions such as estimating the cost per county to transport a material. The ability to understand and successfully manage the data in network analysis and the data flow model to create the final output is crucial in determining accurate conclusions. This exercise challenged way the small details would affect the whole project, but helped me realize the applications network analysis can have.